
Posted by
Share this article
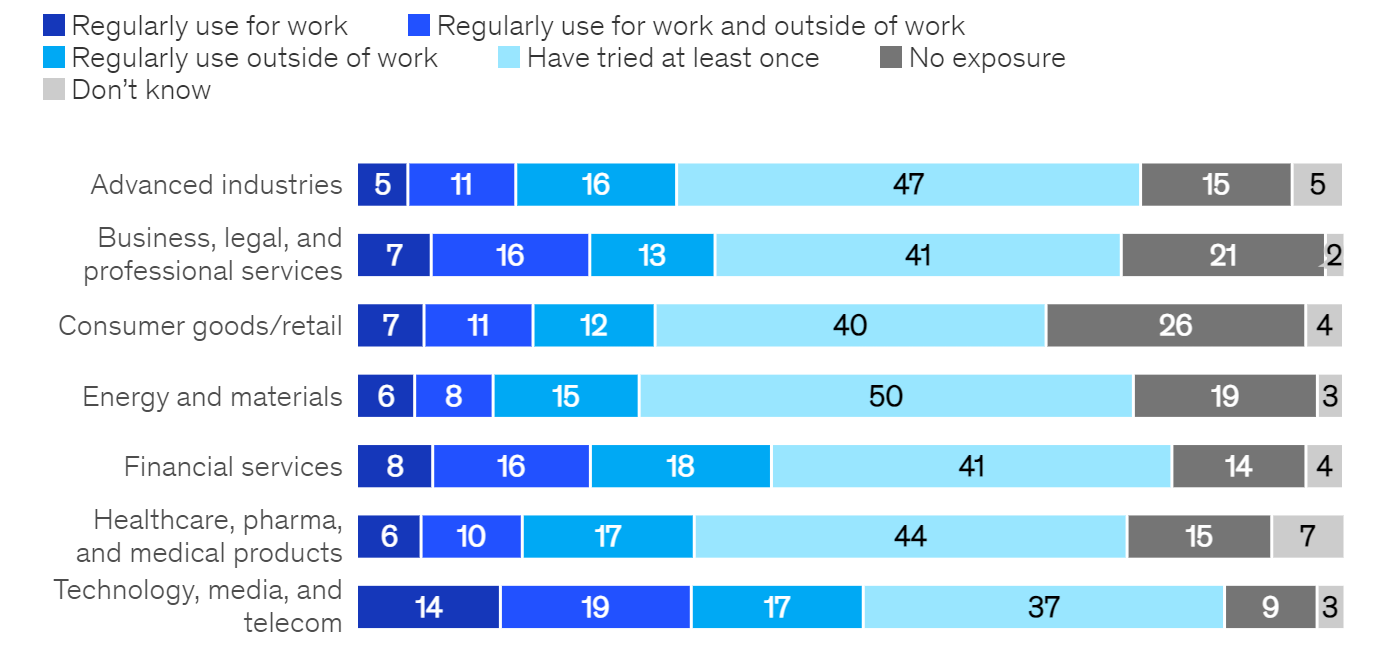
Large Language Models (LLMs) are the latest trend in artificial intelligence (AI), offering unprecedented capabilities to generate realistic and creative text and images. Many businesses are eager to adopt LLMs to enhance their productivity, communication, and innovation. This is partly driven by the increased rate of adoption amongst the workforce. For example, a recent McKinsey report found that up to 22% of professionals regularly use Generative AI for work.
Despite the buzz, business leaders and technical folk working in AI both know there are also many challenges and risks associated with using LLMs. At Thales Cyber Services ANZ Innovation we have been exploring how LLMs could be adopted safely in the workplace to minimise some of these risks. In particular, we were interested to see how well open-source LLMs (which are models that have been publicly released and can be downloaded and hosted on any hardware) live up to this challenge.
In Q3 2023 we examined the state of open source models by evaluating the best models and the best way to serve them. You can check out our findings here: AI in the Enterprise: using open-source models. This blog post provides some of the insights found in the report.

Why use open-source LLMs?
Innovation is happening so rapidly in this area that it seems like a new AI product or feature is announced every week by the major software players. On November 26, 2023, OpenAI announced new models and developer tools to assist in the creation of AI Assistants. What could open-source models possibly offer that companies such as OpenAI, Google, or Microsoft cannot?
1. Privacy
If you control the model, you decide how it stores, accesses, and uses your data. This will always provide a higher guarantee for the privacy of your data.
This level of risk mitigation is not always necessary or required for all enterprises or use-cases. But in some instances it makes sense:
- Hospitals sharing sensitive patient information - some products like ChatGPT enterprise provide an option to comply with HIPAA (Health Insurance and Portability Act), but this may incur an additional expense.
- Government agencies and sensitive data - government agencies usually require data to be physically located within their sovereignty. In some cases, data must be located on-premises and cannot leave an air-gapped network.
- Users handling payment information - Users may inadvertently share sensitive information to a model provider for which it does not meet compliance requirements. For example, OpenAI currently meets SOC-2, but does not handle PCI DSS (Payment Card Industry Data Security Standard).
2. Vendor Neutrality
If language models become a key component in a production application within an enterprise, there is an inherent risk related to being dependent on the model provider. Again, this is a risk which enterprises are familiar with and already manage. Most businesses already leverage cloud platforms such as AWS and Azure to manage their infrastructure.
However, unlike cloud infrastructure, Large Language Models are still in their infancy. Many features and entire models (such as Google’s Bard) are still labeled “experimental” or in “preview”. Their core functionality, privacy policies or features could be pulled out from under your feet - making them unreliable to build on.
3. Flexibility
Models such as ChatGPT are black boxes, and to some extent you cannot modify their behaviour. Sure, they provide you with a finetuning API but this does not offer the level of control and flexibility you get from having a copy of the model because the finetuning method is also a black box which cannot be changed. Open-source models allow you to adapt the model more closely to your use-cases.
4. Redundancy
Businesses running critical services have backups across multiple providers and often a local copy - so that they are not reliant on cloud-hosted data or services in case there is no internet access. The same can be said for AI models. What happens if OpenAI suffers an outage (which is not uncommon) and your users are relying on access to the models to do their work?
You may not need access to open-source models all the time, but they can be handy to use as a backup service.
Which open-source LLM should I use?
So now you understand the tradeoffs and you think you’d like to give open-source models a go. Where do you start? Which model do you pick
The answer is … wait for it … it depends.
The choice of a model depends heavily on what you want the model to do. If you want an all round model to use like ChatGPT - then LLaMA 2 70B is the best choice at the time of writing. Research indicates that LLaMA 2 70B is approximately equivalent to GPT-3.5-turbo when it comes to standard text-generation tasks (excluding code generation or certain reasoning tasks).
However, if your use case is a bit more specific then you need to test how well the model performs under specific scenarios or prompts. We evaluated a bunch of open-source models using two methods - HELM (Holistic Evaluation of Language Models) and a recently popular method of evaluating LLM responses using a judge evaluator model (such as GPT-4).
Key Takeaways
The full set of results from our evaluations, and the reasoning behind our choice of models is provided in our full report. To evaluate open-source models, we asked the judge to analyse responses from models based on 7 different metrics on a scale from 1 to 10, with 10 being perfect. Below is a summary of those results for all the models we tested:
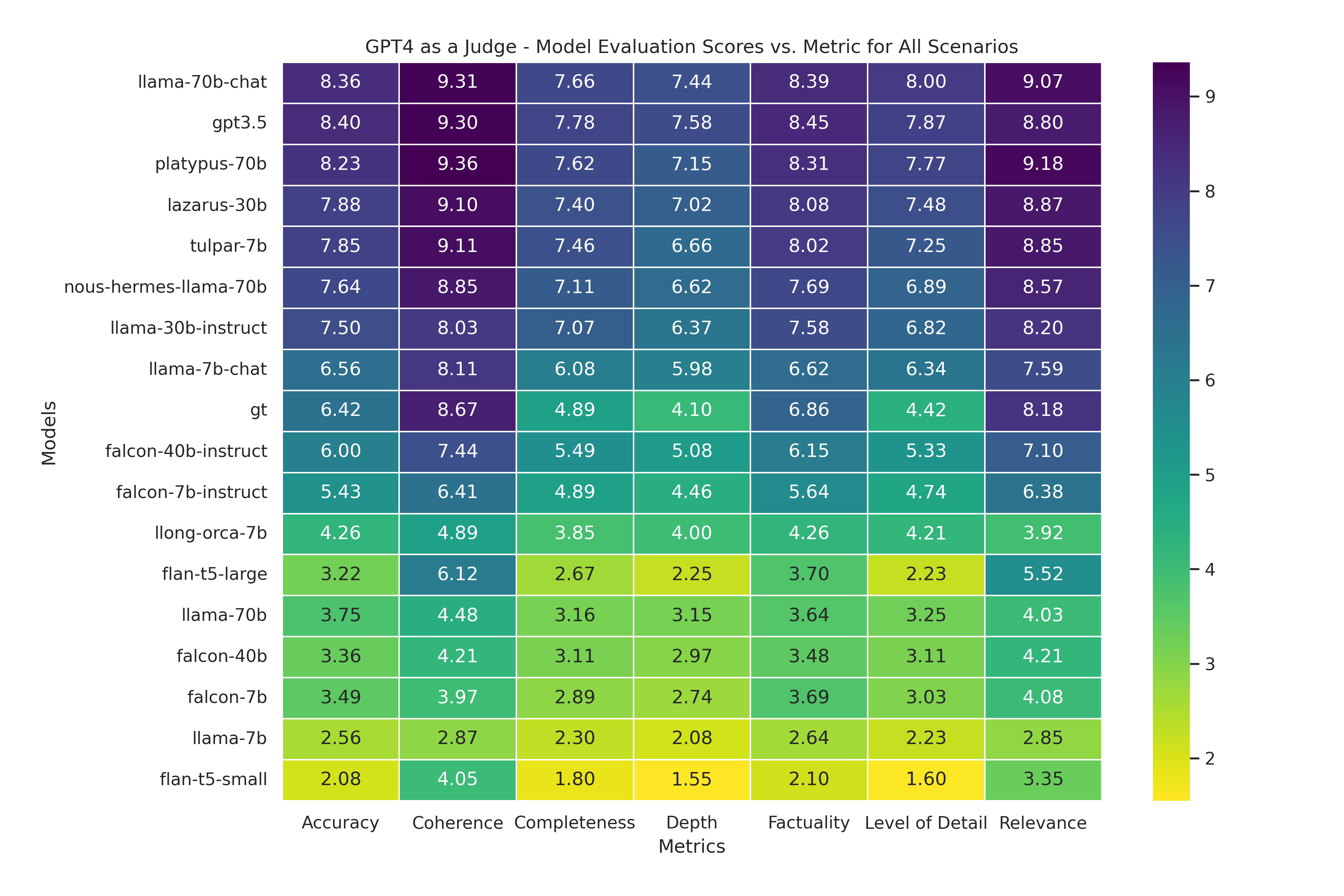
The full set of results from our evaluations, and the reasoning behind our choice of models is provided in our full report. To evaluate open-source models, we asked the judge to analyse responses from models based on 7 different metrics on a scale from 1 to 10, with 10 being perfect. Below is a summary of those results for all the models we tested:
- How you ask matters: LLM models are often pretrained with input data in a specific format. When performing inference, these models produce outputs of a much higher quality when prompted using the same format that was used in training. HELM does not use model-specific prompts in its evaluations, whereas we used model-specific prompts in our LLM-as-a-judge evaluation. Falcon and LLaMA 7B chat models performed much poorer in HELM (among the worst in all scenarios) compared to LLM-as-a-judge (average or slightly above average). And in a more dramatic result, LLaMA-70B-Chat went from a middling performer in HELM to the best overall performer in the LLM-as-a-judge evaluation. To get the most out of your model, you must prompt correctly.
- Small models can punch above their weight: In both evaluations, certain small models did surprisingly well for their size. One standout was Tulpar-7B – which came 4th in the LLM-as-a-judge evaluation. Tulpar-7B appears to do particularly well in responding without Bias and toxic content.
- Some models keep it short and sweet: Some models such as flan-t5-large respond with terse text (low depth score), but often with high coherence and relevance. This may be useful for classification tasks where you only want a yes/no answer or where the output of the model is used to feed another system. Flan-t5-large is tiny and can be hosted on most commodity hardware.
Do your own research
Don’t just take our word for it though. You should test these models out for yourself. On your own data. Data science and AI engineering teams have been running benchmarks and evaluations on models for years, and it makes sense to leverage that knowledge. But generative AI has also made AI accessible to a wider audience - which allows any team to experiment with models.

If any of this sounds too hard, or you don’t have enough in-house expertise to set this up, we’d be happy to help.
Meet Judy
During the process of assessing evaluation tools, we realized there are no comprehensive tools designed specifically to assist in evaluating models using a judge LLM. And none of them could easily incorporate new evaluation scenarios and methods which are being published at a rapid pace.
So we created Judy - It’s a tool and framework to evaluate LLMs using a Judge evaluator. It’s also got a web app where you can keep track of your results.
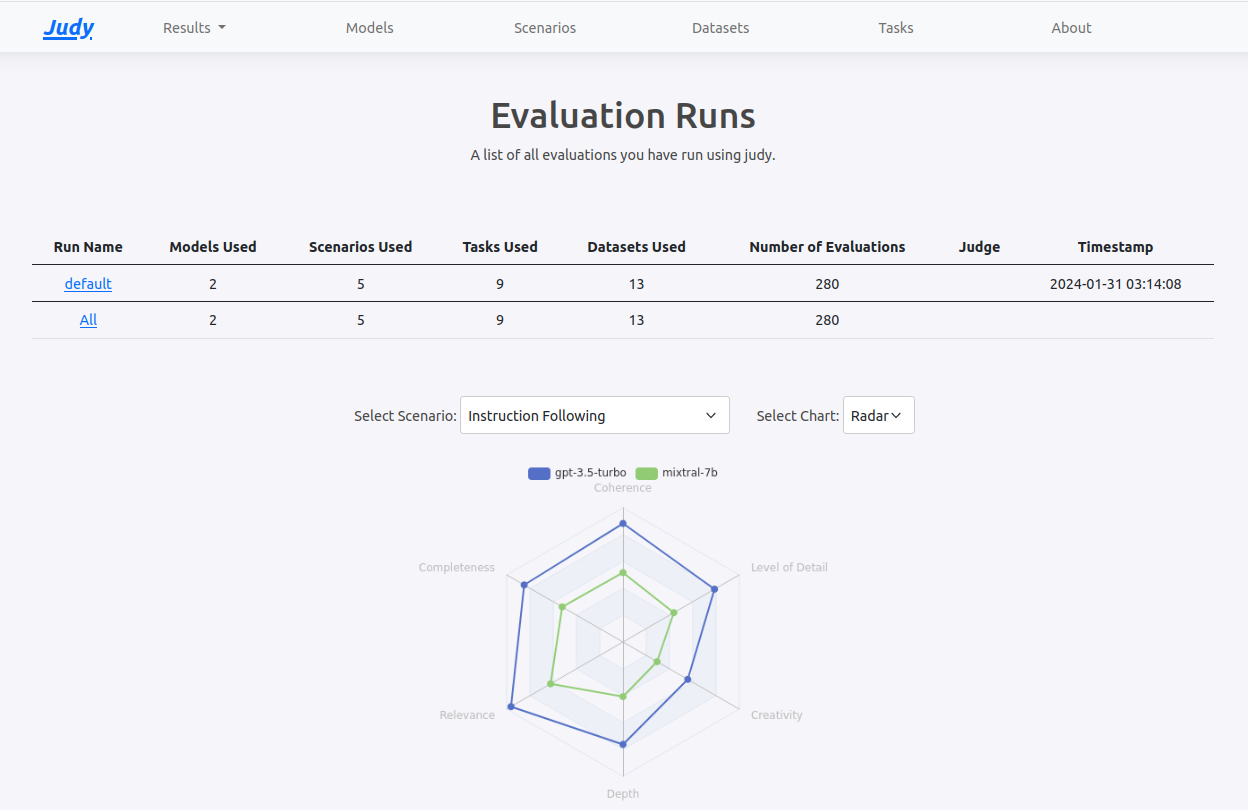
We’re excited about where the community takes it. Try it out today! -
Contact us
Speak with a Thales Cyber Services ANZ
Security Specialist
Thales Cyber Services ANZ is a full-service cybersecurity and secure cloud services provider, partnering with clients from all industries and all levels of government. Let’s talk.

